What is Crisp-DM Methodology?
In this post we’ll take a look at what CRISP-DM methodology is and why it’s very useful in data management projects.
Firstly, CRISP-DM stands for Cross-Industry Standard Process for Data Mining. It is a popular decision sequence used by data scientists.
A consortium of organisations developed CRISP-DM. It consisted of data science vendors, end users, consultants and researchers. It is popular because it provides a sensible framework for data science projects. The framework is iterative too, so you can step forward and back between phases.
CRISP-DM as a methodology
As a way of working it includes descriptions of the project phases. It also covers the tasks for each phase. And then an explanation of the relationship between the tasks. Data scientists might use other methods, but the iterations of CRISP-DM works.
The steps are easy to identify and project briefings work well too. Everyone will know what stage the project is at.
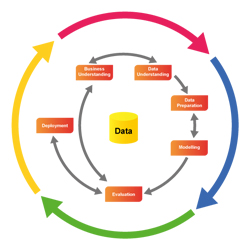
CRISP-DM as a process model
The model has six phases:
- Business understanding
- Data understanding
- Data preparation
- Modelling
- Evaluation
- Deployment
Business & data understanding
The first two stages are where data scientists try to define the goals of the project.
They’ll do this assessing the business needs and the data available to the business.
The iterative process starts early. That’s because data scientists will switch between the business and the data available.
This phase is where your business question is set and a deep dive into the data you have available begins.
That will identify if the data needed to answer the business question is available. And if not, will it be possible to extract the required data?
Data preparation
The next phase is data preparation. The purpose here is to make sure there is a data set available for analysis.
It might be necessary to merge data from many sources. And the data may need cleaning to ensure that analysis will be successful.
Modelling
This is the technical part. It’s where algorithms look for useful patterns in the data.
It is where machine learning (ML) joins in. Data scientists will use algorithms to train different models on the given data set.
Patterns that are useful get returned from the models. And these help to achieve the project goals.
Running the models again with new or updated data is also possible. That means decisions and predictive modelling is up to date.
Evaluation and deployment
These stages focus on how the model fits the business and its processes.
Tests run during the modelling stage focus on the accuracy of the models for the data set.
The evaluation phase is about making sure the model meets the business objectives. You know the model(s) work at this stage. But now it’s time to make sure they are delivering the output needed.
Deployment into the working processes of the business should be seamless. If the other stages have resolved then the ML output will be answering the business question(s).
From the world of statistics…
There is a similar framework called PPDAC that statisticians will be familiar with. The phases are:
- Define the problem
- Establish the approach and make a plan
- Gather the required data
- Carry out analysis of the data
- Review the conclusions uncovered in the analysis.
- You’ll notice that CRISP-DM is like this framework and for good reason.
Although PPDAC comes from statistics, data science does involve statistical analysis too. Hence the similarities between the two frameworks.
Augmented Insights uses the CRISP-DM model with our clients. So if you’d like to find out more, why not get in touch with us to ask about how we can help